
How many articles and papers have been written over the years talking about data center networks getting faster, denser, bigger, and more efficient? Then every time the next generation of networking speed comes out, they say it is not possible to go any faster.
Back in the early 2000s, when data centers were little more than communications rooms or exclusively used in large financial institutions, the start of the Ethernet speed race began. What started with 10GBASE-SR, which was a multimode 10G transmission at 850 nm, speeds began to increase to 40G in the guise of 40GBASE-SR4, combining four lanes of 10GBASE-SR, and then came 100GBASE-SR10, which promised to deliver 10 lanes of 10G to yield the dizzying speed of 100G. While the 100G 10 lane variant never really made it into the mainstream, the trend of a base speed and a 4X multiplier was born.
Fast forward to 2010 with the birth of both “The Cloud” and the “Hyperscale” data center. The phenomenon of the cloud, plus millennials and young engineers that were coming on the scene, led to a change in speed. We started seeing open compute, bare metal switches, and application-specific network switch operating systems. New tech-savvy giants were not happy with the pace at which they could grow their networks, so they started forming partnerships with switch ASIC manufacturers, bare metal switch manufacturers, and transceiver manufacturers. They also started developing their own bespoke systems that allowed them to grow and scale their network fabrics larger and faster than ever dreamed possible. This was the point that the gulf between the enterprise data center and the cloud data center opened and grew exponentially over the following years.
In the hyperscale world, multimode 40GBASE-SR4 was quickly replaced with 40GBASE-PSM4, which was essentially the same four-lane transmission as its multimode predecessor but used single-mode fiber. This change enabled extra transmission distance in the ever-increasing footprint of data centers. The other huge advantage of this four-lane aggregation was that it could be disaggregated, meaning the network could scale to a greater size. A single, four-lane network port could now connect to four other network ports, or end devices, effectively quadrupling the scale of the network.
Once these newly formed alliances among ASIC, bare metal switch, and transceiver developers and hyperscalers started to formalize into formal multi-source agreements (MSAs), the Ethernet development curve steepened. 40GBASE-PSM4 was short lived, becoming outdated with the advent of a 25G-per-lane transmission. And, a four-lane, 25G, 100GBASE-PSM4 was born. This new approach enabled a seamless upgrade for hyperscalers to utilize their existing fiber infrastructure and architecture.
Not only does all of this exponential growth in Ethernet transmission speeds allow you to move bits and bytes around the data center quicker, but more importantly, it allows the switch fabrics to grow larger due to far greater interconnect speeds. With the increasing size of the core switch fabric, the overall network size grows, and the number of cabinets, servers, and end devices also grows. These larger physical networks, often spanning multiple buildings on the same campus or in the same locale require increasing amounts of ultra-high fiber count (UHFC) cables to enable these data center interconnects.
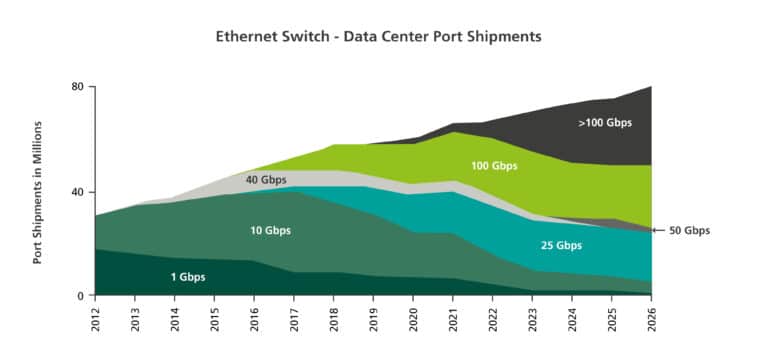
The rapid progress in ethernet port transmission speeds could never have happened without the evolution of the switch ASICs, which supported the ability to switch data packets at these speeds. Typically, at the front of the Ethernet switch ASIC evolution was Broadcom, who has consistently doubled speeds every two years since 2010. They started with their Trident switch at 640G, then Trident 2 at 1.28T in 2012, and Tomahawk 1 through 5 in 2014, 2016, 2018, 2020, and 2022. Their most current switch is a 51.2T single ASIC switch chassis.
With the 51.2-TB ASIC inside the long-standardized 1RU bare metal switch chassis, it could theoretically be configured with 32 ports of 1.6 TB each. While there are no commercially viable intra-data-center 800G pluggable transceivers shipping in volume, they are used in many networking labs and are not far from mass deployment. That is unless these hyper networks decide to skip a generation and take full advantage of the 32X 1.6-TB switching capability and go straight to 1.6 TB.
As with most things Ethernet, backwards compatibility, and more importantly interoperability, is critical for each evolution. This is the case for the 51.2T ASIC, with offerings now emerging with 64X 400G ports, 128X 200G ports, and 265X 100G ports.
Artificial Intelligence, Machine Learning and High-Performance Compute
While all of this exponential growth was occurring on the networking side of the data center, the server, storage, and processing side was experiencing the same rapid evolution. The introduction of the smartphone and the Internet of Things significantly changed the processing type in the data center. The cloud was no longer performing commercial tasks and running businesses; it was now servicing an individual’s daily life.
The concept of Big Data has been around since the early 1990s, but the ability to crunch, decipher, and act on the data is still evolving. It is now estimated that 1.15 exabytes (one trillion megabytes) of data are created daily. All of this information needs to be manipulated into meaningful, useful data, with high-performance compute, machine learning, and artificial intelligence – all of which can be summed up as HPC.
The split of traditional compute and storage instances in the data center versus HPC instances now leans heavily towards the HPC side, bringing new challenges. Since its inception, HPC fundamentally combines multiple CPUs or GPUs into a cluster to perform a specific task. The biggest change over the evolution of HPC is simply that the clusters have grown from a few GPUs in a server to a few servers in a rack, to a few racks in a row, to a few rows in a data center, and so on.
Regardless of how large the cluster grows, each of the processors in that cluster needs to communicate in the most efficient way with every other processor in the cluster for them to operate as a single unit. This need for “cluster unification” requires all of the nodes to be highly interconnected with very dense networking and interconnect at the highest speeds possible, leading to exponential increase in fiber connection density.
Infrastructure to Handle Growth
Over the past 20 years, while data centers were growing in size and quantity, networks were accelerating at a rapid rate. Additionally, compute and storage were evolving, so the fiber infrastructure supporting the data center had to evolve as well. That said, a lot of the base building blocks have remained constant (although not static). Connectors of choice have remained the LC duplex and MPO BASE-12 or MPO BASE-8, and single-mode fiber has been enhanced with respect to loss and bend performance, but it has not fundamentally changed. These building blocks have been through tremendous change and similar growth curves to the networking speeds.
One of the most obvious examples of change has been the fiber counts of individual cables deployed inside the data center. Going back to the birth of the cloud, a high-count fiber cable in a data center would have been 96 or 144 fibers. In today’s networks, it is not uncommon to see fiber cables with 6,912 fibers – with surprisingly small diameters and craft-friendly, easy handling. These UHFC cables are enabled by today’s modern flexible ribbon technology, which use ultra-handleable, rollable 12-fiber ribbon, combined in bundles to fiber counts from 288 up to 6,912.
Coupled with the latest generation of ribbon technology are the necessary fiber management solutions and accessories to install and operate these cables in the simplest manner. This goal targets both the contractor installing the solution and the operator manging the solution over its life span. The accessories range from specialized breakout solutions, all the way through to mass fusion splicing innovations, allowing rapid splicing and termination of these UHFC cables. For solutions to land the cable there is a full ecosystem of products that allows the termination of the cable in all areas, from splice closures to ultra-high-density entrance facility solutions and rack-mount high-density modular platforms.
Although the basic building blocks have not changed significantly over the past 20 years, we are now at a major point of inflection on all these basic blocks, and the next two to five years could see the basic infrastructure in the data center change significantly. The MSAs mentioned above are releasing new standards for new 800G and 1.6T transceivers with various fiber connection methods or Physical Media Dependencies (PMDs). This calls for new connectors and significantly different lane counts. Up to 400G, a significant portion of the deployed transceivers were the 400GBASE-DR4, which has four lanes (eight fibers) of 100G connected with an MPO8 connector. Moving to 800G and 1.6T, the MSAs are publishing PMDs that deploy 800G as eight lanes of 100G, utilizing 16 fibers and deploying a whole new suite of fiber connectors known as very small form factor (VSFF) in both duplex and BASE-16 variants.
In migrating to 1.6T, the lane speed would need to increase to 200G for a BASE-16 solution or to 400G for a BASE-8 solution, both of which are challenging but not infeasible. The other option that is rapidly developing takes the fiber and the optics deeper into the switch chassis, off the front plate and straight onto the board with on-board optics. Coupling on-board optics with multi-core fiber (a single-mode fiber that has four cores rather than a single central core) could lead to very significant changes in networking and potential speeds. With all of these potential changes, we are entering a very exciting period for data center networking and the supporting fiber infrastructure.
Keith Sullivan is the director of strategic innovation – hyperscale at AFL. With over 27 years of experience, Keith is an accomplished business leader in the fiber-optics industry with a specialty in data centers. He started his career in 1995 in a factory in England producing specialty fiber assemblies for high-speed devices in the telecom industry. Since then, he has worked for industry-leading organizations in sales, marketing, and product line management.
